图的构成
顶点集合+边的集合:G = (V, E),顶点集合V = {x | x属于某个数据对象及}是有穷非空集合
E = {(x, y) | x, y属于V}或者E = {<x, y> | x, y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫边集合(x, y)表示x到y的一条双向通道,即(x, y)是无方向的,Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的
顶点和边:图中节点成为顶点,第i个顶点记作vi, 两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中第k条边记作ek,ek = (vi, vj)或ek = <vi, vj>
- 在有向图中,顶点对
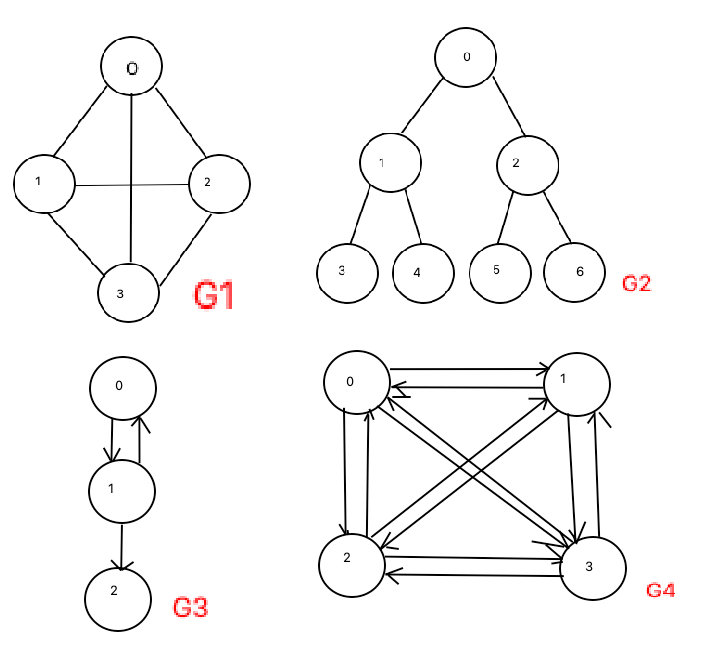
<x, y>是有序的,顶点对<x, y>称为顶点x到顶点y的一条边(弧),<x, y>和<y ,x>是两条不同的边,如G3、G4 - 在无向图中,顶点对(x, y)是无序的,顶点对(x,y) 称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,如G1、G2
- 注意:无向边
(x, y)等于有向边<x, y>和<y, x>
可以表示:社交关系
- 社交关系中,每个人就是一个顶点,两个人是好友,他们之间就有了边,那么边的权值可以是他们的亲密度
- 无向图:QQ、微信类似的社交关系可以被看作是无向图(强社交关系,熟人社交)
- 有向图:微博(关注的关系)、抖音 (弱社交关系,陌生人社交、粉丝社交)
- 也可以用来表示地图(导航路线选择),网络连接(路由器选择)
- vertex 顶点、edge 边、weight 权值
相关概念
- 完全图(即所有顶点相连接):在有n个顶点的无向图中,若有
n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,如G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向 相反的边,则称此图为有向完全图,如G4。 - 邻接顶点:在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u 和v;在有向图G中,若是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边与 顶点u和顶点v相关联。
- 顶点的度:顶点v的度是指与它相关联的边的条数,记作
deg(v)。在有向图中,顶点的度等于该顶点的入度与 出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向 边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶 点的入度和出度,即dev(v) = indev(v) = outdev(v)。 - 路径:在图
G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从 顶点vi到顶点vj的路径。 - 路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路 径的路 径长度是指该路径上各个边权值的总和。
- 简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路径。若路 径上 第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环。即路径不重复为简单路径,重复则为回路
- 子图:某个图的一个部分(一部分边、一部分顶点等)称为其的子图
- 连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一 对顶点 都是连通的,则称此图为连通图。(连通图不一定是完全图,但完全图一定是连通图,对连通图来说,仅需有路径即可,而完全图则要求两顶点邻接)
- 强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到 vi的路 径,则称此图是强连通图
- 生成树(用最少的边把图连通):一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n - 1条边。
- 图和树的区别:
- 树可以认为是特殊的图,图不一定是树
- 联通图,且不带环(没有回路),就可以认为是树
图的存储结构
保存节点以及边的关系
邻接矩阵
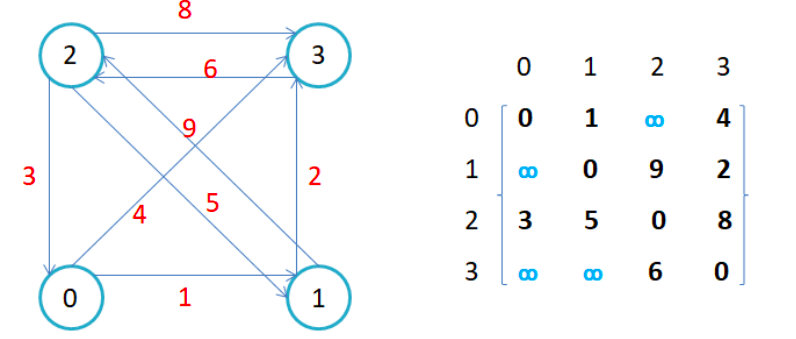
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即是:先用一个数组将顶点保存,然后采用矩阵来表示节点与节点之间的关系。
用vector<char> vertex保存顶点,用矩阵vector<vector<W> > edge保存边,如下
用vector<char> vertex保存顶点,用矩阵vector<vector<W> > edge保存边,如下
- 无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称 的,第i行(列)元素之后就是顶点i 的出(入)度
- 如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通, 则使用无穷大代替
- 用邻接矩阵存储图的有点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩 阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
邻接矩阵代码实现
1 | //vertex 顶点 |
邻接表
使用数组表示顶点的集合,使用链表表示边的关系。
- 图为无向图的邻接表存储
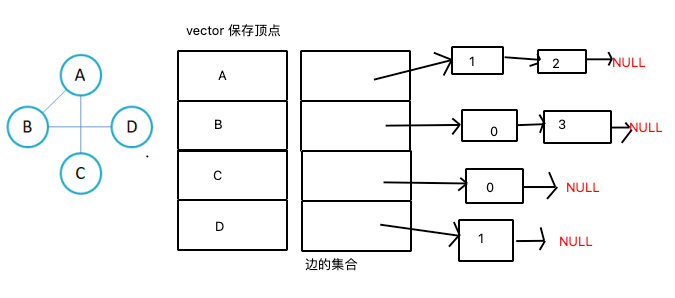
- 注意:无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可
- 有向图则添加一个边的集合或者反向添加一次
邻接表的代码实现
1 | namespace table |
图的遍历
给定一个图G和其中任意一个顶点v0,从v0出发,沿着图中各边访问图中的所有顶点,且每个顶点仅被遍历 一次。”遍历”即对结点进行某种操作的意思
图的深度优先遍历
对邻接矩阵,深度优先可是使用递归的方式实现
1 | void _DFS(int srcIndex, vector<bool>& visited) |
图的广度优先遍历
对邻接矩阵,广度优先可以使用队列实现
1 | void BFS(const V& src) |
最小生成树
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树就不再连通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。因此构造最小生成树的准则有三条:
- 只能使用图中的边来构造最小生成树
- 只能使用恰好n-1条边来连接图中的n个顶点
- 选用的n-1条边不能构成回路
构造最小生成树的方法:Kruskal算法和Prim算法。
- 这两个算法都采用了逐步求解的贪心策略。 贪心算法:是指在问题求解时,总是做出当前看起来最好的选择。也就是说贪心算法做出的不是整体最优的选择,而是某种意义上的局部最优解。贪心算法不是对所有的问题都能得到整体最优解。
Kruskal算法
任给一个有n个顶点的连通网络
N={V,E}首先构造一个由这n个顶点组成、不含任何边的图
G={V,NULL},其中每个顶点自成一个连通分量- 接着不断从E中取出权值最小的一条边(若有多条任取其一),若该边的两个顶点来自不同的连通分量,则将此边加入到G中。
- 如此重复,直到所有顶点在同一个连通分量上为止。
- 核心:每次迭代时,选出一条具有最小权值,且两端点不在同一连通分量上的边,加入生成树。
如何判断选出一条边以后跟已有的边是否构成回路:并查集
如果选的边在一个集合中,就不能再使用,不在一个集合才能添加
Prime算法
仍是贪心算法,但它先选出最小的一条边,接着并非从全局中找到最小的边,而是以最小的边为基础,选已有的边的邻接顶点链接出的边中最小的,避开了选出环路的情况
单元最短路径
从在带权图的某一顶点出发,找出一条通往另一顶点的最短路径,最短也就是沿路径各边的权值总和达到最小。
Dijkstra算法和Floyd算法
Dijkstra算法
求一个点和图中的其他所有点之间的最路径
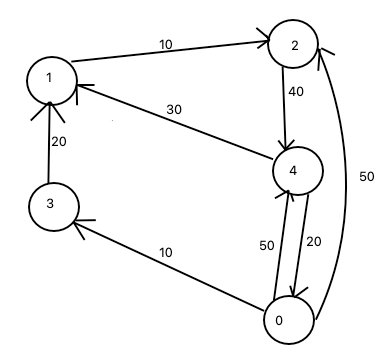

| 路径 | 路径长度 |
|---|---|
| 0,1 | 无穷大 |
| 0,2 | 50 |
| 0,3 | 10 |
| 0,4 | 50 |
依次遍历所有的边,找出更短路径,找到则更新